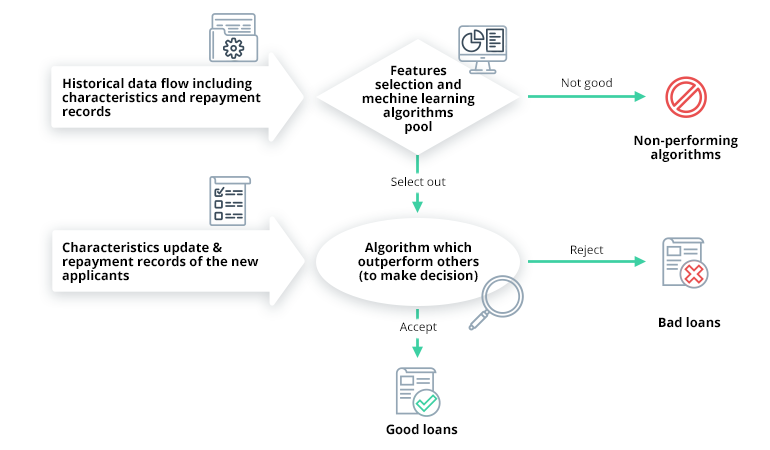
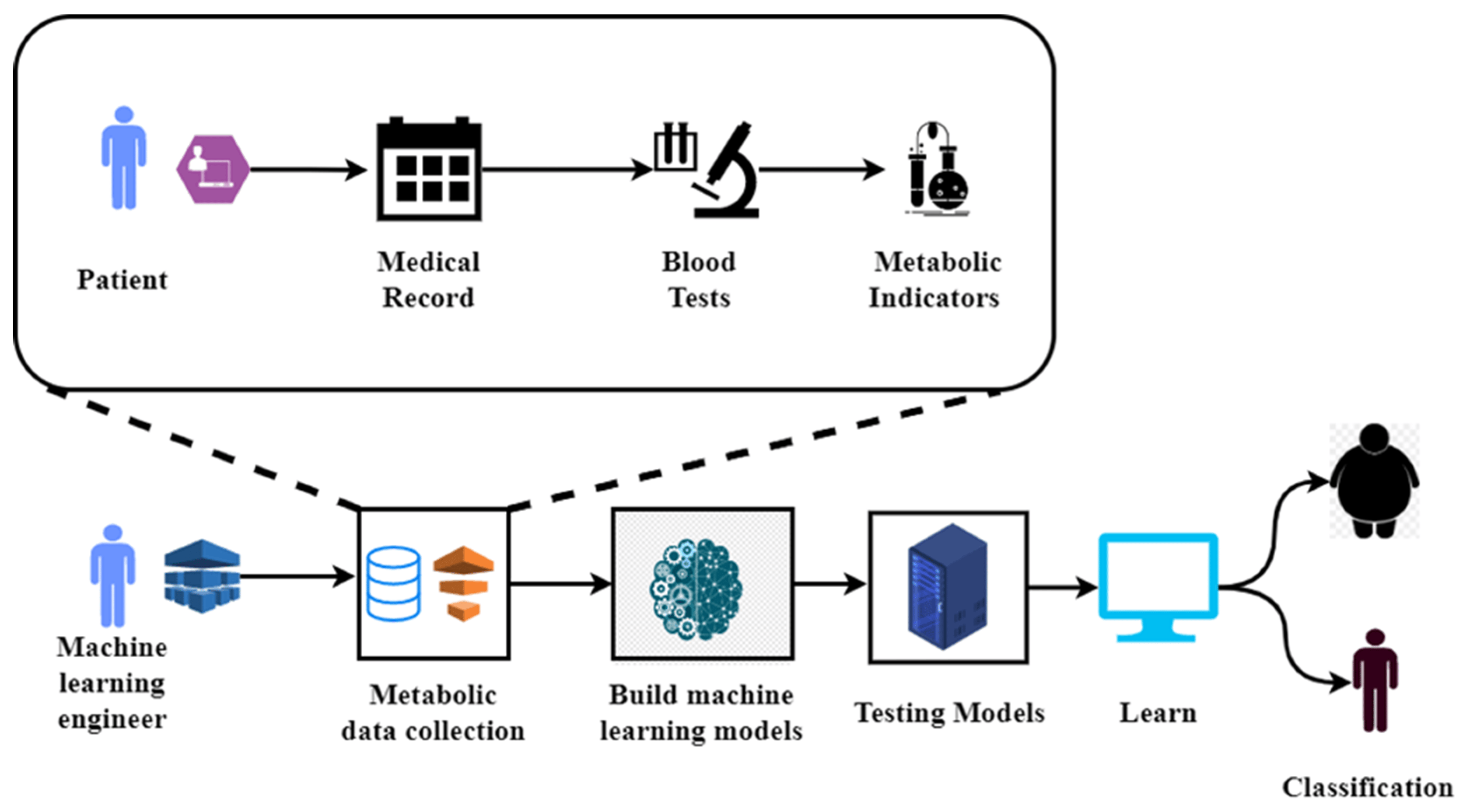
ML for Tabular & Sequential Data

Trustworthy AI: Beyond Accuracy
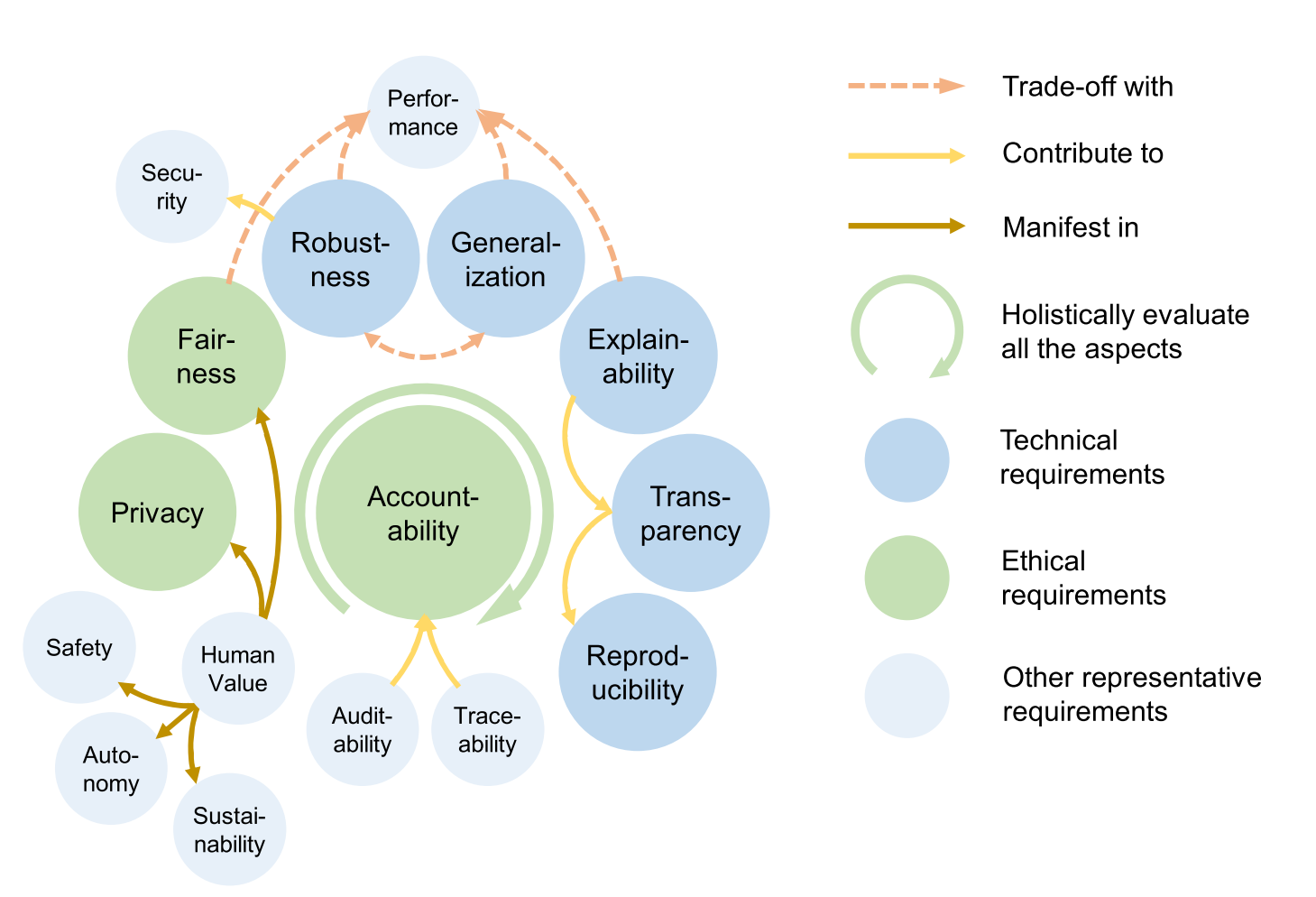
Adversarial Robustness
What are Adversarial Attacks?
Adversarial examples are specialised inputs created with the purpose of confusing a neural network, resulting in the misclassification of a given input. These notorious inputs are indistinguishable to the human eye but cause the network to fail to identify the contents of the image. (Goodfellow, Shlens, and Szegedy 2015)

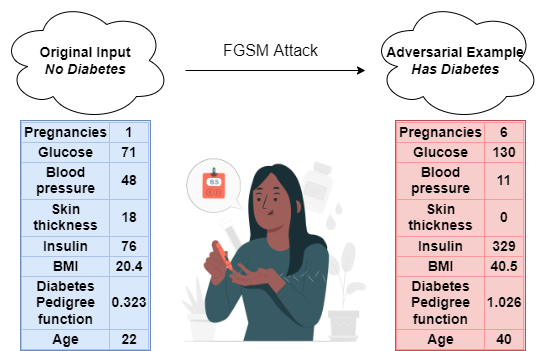
- Mislead the prediction 😊
- Similarity ❓ \(\Longrightarrow\) What makes a good adversarial attack?
Input Data: Image VS Tabular (Mathov et al. 2022)
Image (unstructured):
- High-dimensional
- Homogeneous
- Continuous & consistent features
Tabular (structured):
- Low-dimensional
- Heterogeneous
- Numerical & categorical features
- Feature dependencies


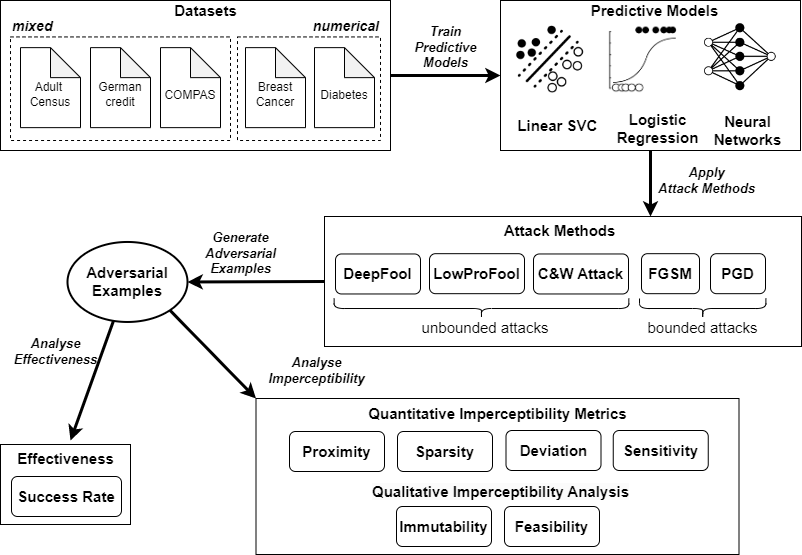
Experiment Pipeline
Finding 1
Phase 2.3
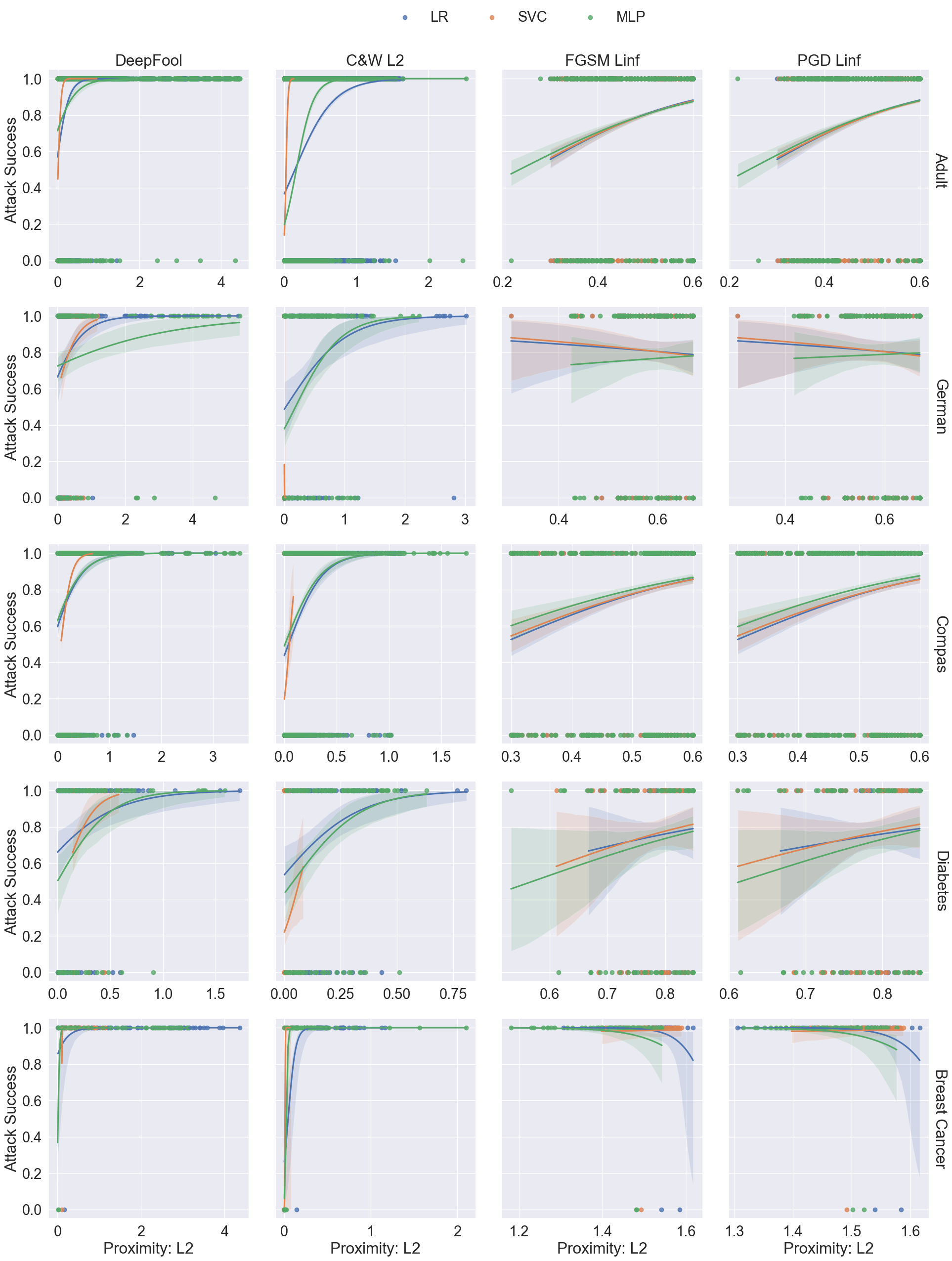
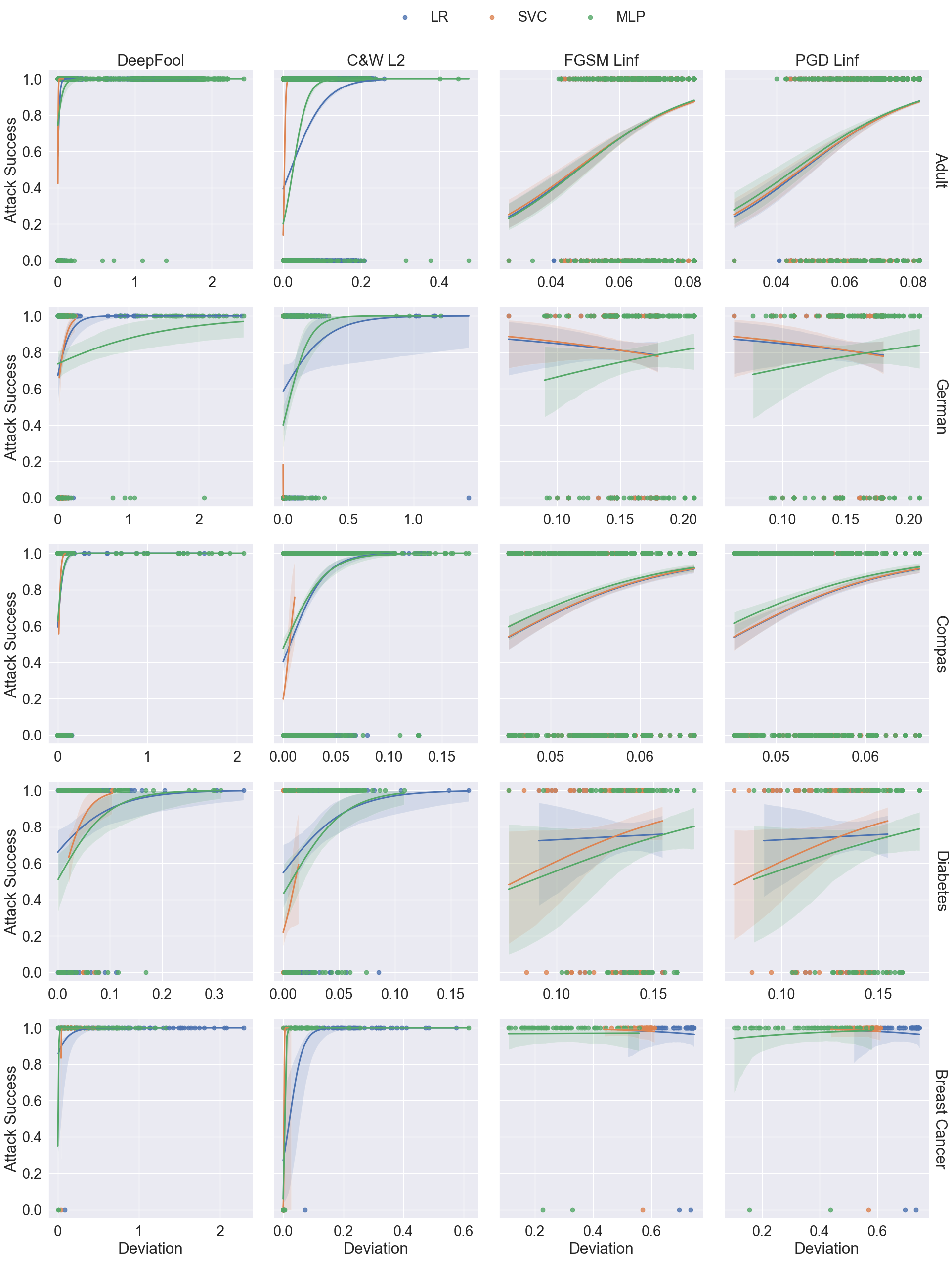
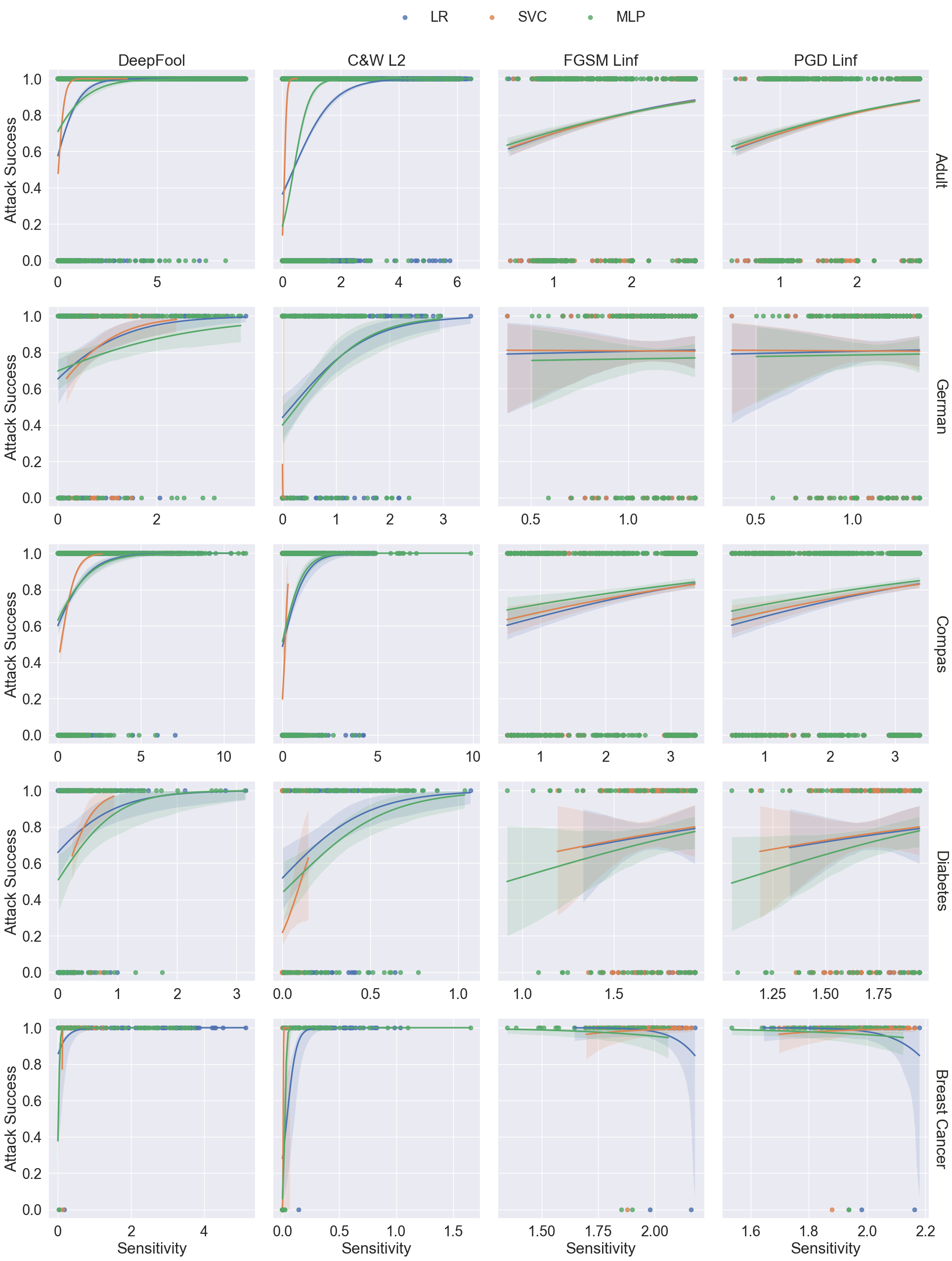
There is a trade-off between imperceptibility and effectiveness.
Qualitative Analysis: Immutability

- Likelihood of reoffending are flipped from
Medium-LowtoHigh; - but the feature values of
Raceare changed.
Qualitative Analysis: Feasibility
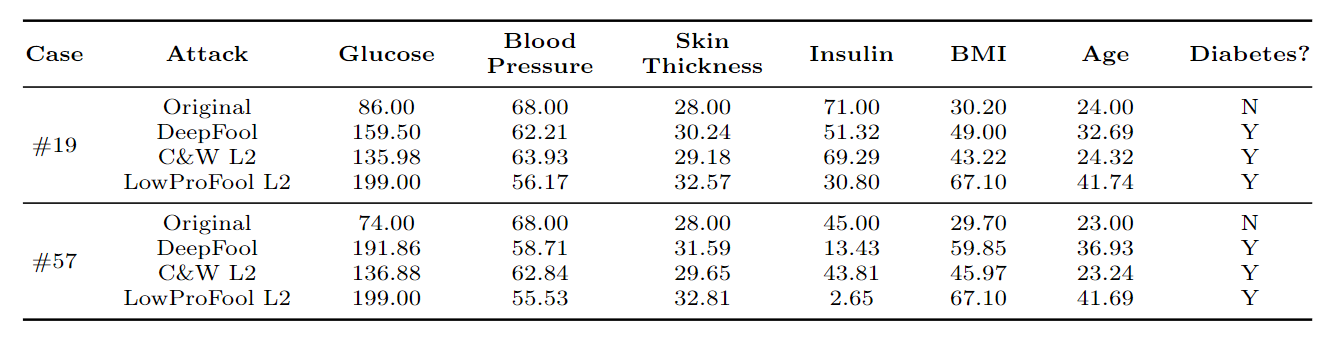
- From medical domain knwoledge, the feasible range of BMI is from 15 (Underweight - Severe thinness) to 40 (Obese Class III).
Future Work
Thank you!
- github.com/ZhipengHe/Imperceptibility-in-Adversarial-attack
- slides.zhipenghe.me/2023-IS-DC
- with by Zhipeng “Zippo” HE with Reveal.js & Quarto